Constitutional AI
论文阅读记录
Constitutional AI
- 标题:Constitutional AI: Harmlessness from AI Feedback
- 作者:Anthropic
- 年份:2022
- 链接:Cai
Main
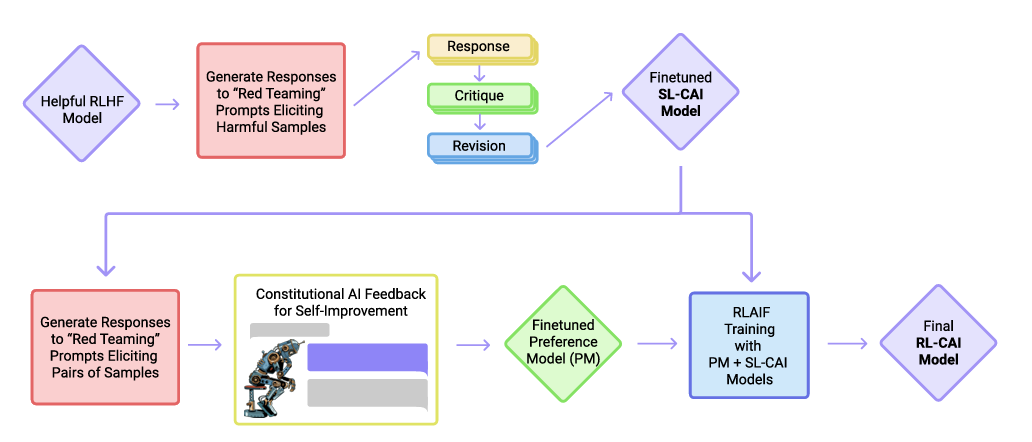
Framework:
Motivation:
Scaling Supervision: leverage AI to help humans to more efficiently supervise AI
- AI supervision may be more efficient than collecting human feedback
- AI systems can already perform some tasks at or beyond human level
- Visualization:
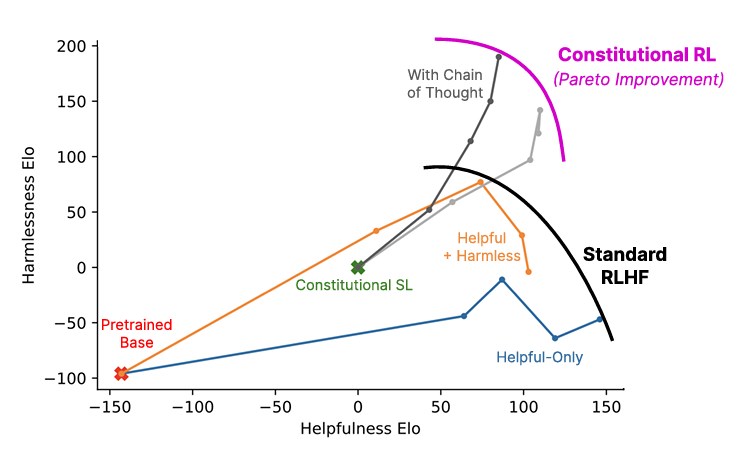
A Harmless but Non-Evasive (Still Helpful) Assistant
Simplicity and Transparency
The Constitutional AI Approach: human supervision will come entirely from a set of principles
- (Supervised Stage) Critique → Revision → Supervised Learning
- (RL Stage) AI Comparison Evaluations → Preference Model → Reinforcement Learning
Models and Data: Helpful Model (H), Helpful & Harmless Model (HH)
Constitutional AI: Critiques, Revisions, and Supervised Learning:
- Method:




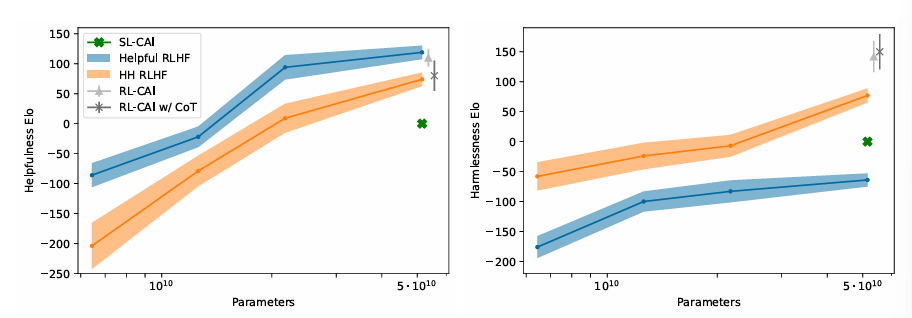
- Results:
- H-RLHF
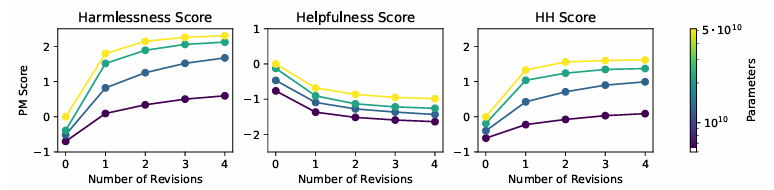
- Numbers of Revisions
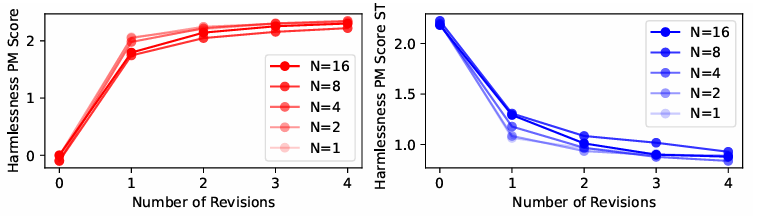
- w/o critique
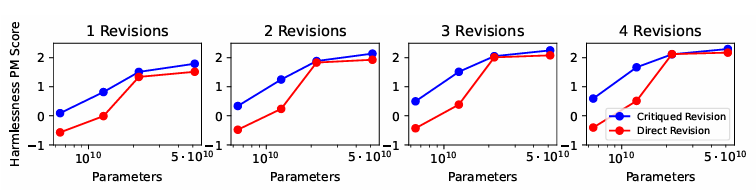
- H-RLHF
- Method:
Constitutional AI: Reinforcement Learning from AI Feedback
Method:



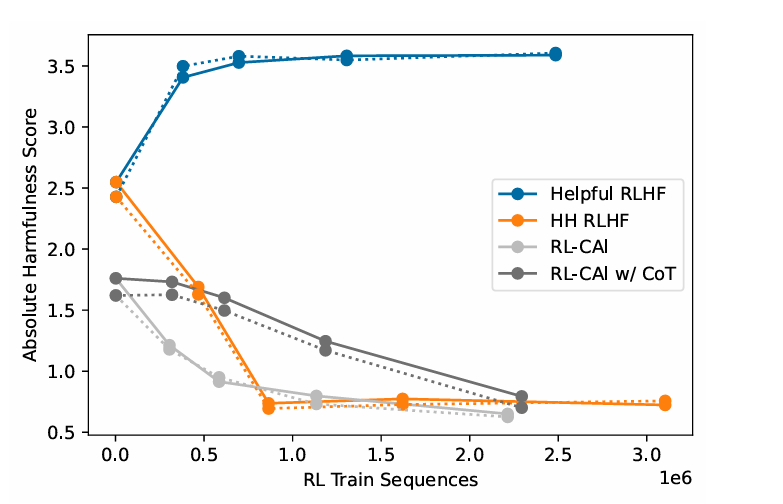
Results:
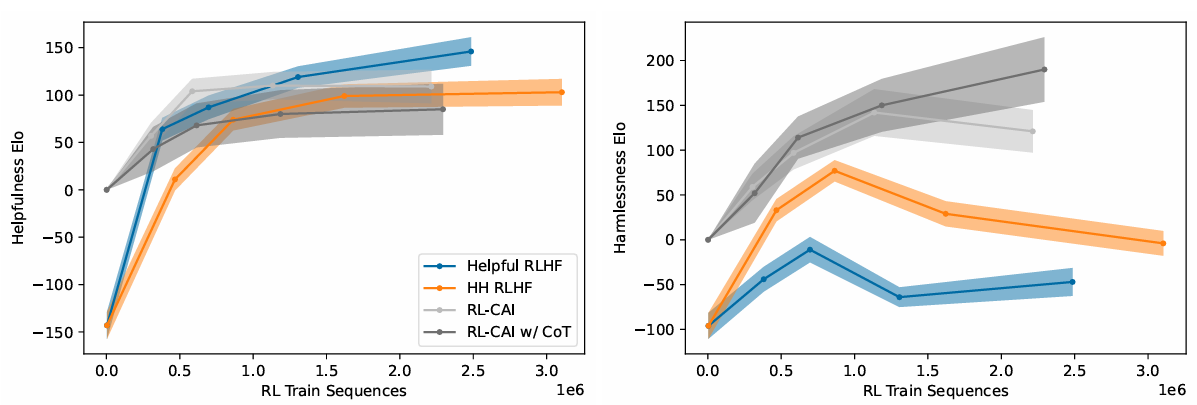
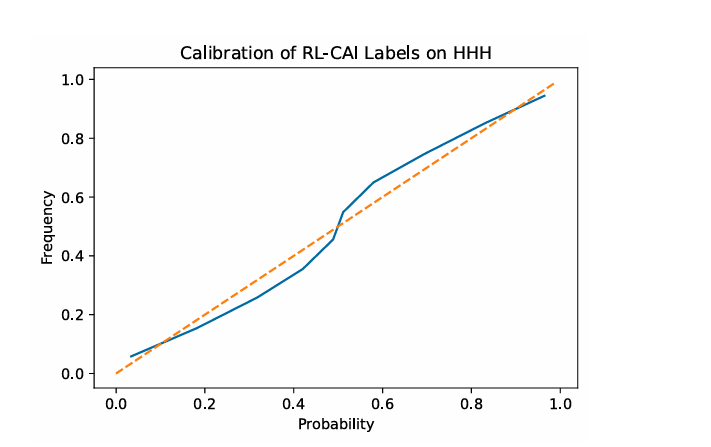

optimization:Constitutional Principles, Ensembling, Preference Labels (Soft vs. Hard vs. Clamped)
Harmlessness vs. Evasiveness
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 小鱼日记!